
Project Descriptions
You can find descriptions of all the projects below:
overview
Autonomous Underwater Vehicle (AUV-IITB)
AUVSI and ONR’’s International Robosub Competition, San Diego, USA
Vision (Spring 2012 - Spring 2013)
Guides: Dr. Hemendra Arya and Dr. Leena Vachhani
[Journal Paper (2012)] [Journal Paper (2013)]
Designing and developing an unmanned autonomous underwater vehicle (AUV) that localizes itself and performs realistic missions based on feedback from visual, inertial, acoustic and depth sensors using thrusters and pneumatic actuators. Matsya (sanskrit word for fish) is the AUV from IIT Bombay to participate in the International Robosub competition, San Diego which sees teams of different universities from countries all over the world.



More information about the competition can be found here. Details about the AUV IITB team are present here.
Machine vision for Autonomous Underwater Vehicles poses three important challenges:
- Degraded image quality due to the medium—Low visibility, color casting (blue or green), poor constrast, varying illuminations, brightness artifacts and blurring are of primary concern. Hence, pre-processing of images to correct these degradations is necessary to ensure robust detection in later stages of analysis.
- Limited on-board computational capacity—Since the vehicle has a centralized processor and a plethora of sensors and other peripherals, power management is of utmost importance. Such a conservation lays a direct contraint on the amount of computing available for the current mission. This eliminates the scope for using processor-intensive techniques thereby increasing the challenge further.
- Real-time requirement for navigation of the machine—The two on-board cameras are an importance source of feedback for the vehicle. For a reliable navigation and actuator control, detection algorithms have an additional condition of real-time execution.
To tackle the above problems, we devised adaptive identification and correction of color casts in images, edge-saliency based color segmentation and adaptive enhancement based on corrected color cast, amongst other techniques formulated after thorough literature survey.
####References:
- Zuiderveld, Karel. Constrast Limited Adaptive Histogram Equalization.
- P. Felzenszwalb, D. Huttenlocher. Efficient Graph-based Image Segmentation.
- Finlayson, G.D., E. Trezzi. Shades of Gray and Color Constancy.
- Cosmin Ancuti, Codruta Orniana Ancuti,Tom Haber, Philippe Bekaert. Enhancing underwater images and vides by fusion. Computer Vision and Pattern Recognition (CVPR), 2012
Static Vehicle Detection and Analysis in Aerial Imagery using Depth
Internship at IRIS, University of Southern California, Summer 2013
Guide: Prof. Gerard Medioni
[Report] [Poster]
Vehicle detection and identification in urban scenarios has many civilian, security and surveillance application. The easy availability of aerial images along with its advantage of spanning wide areas due to large field of view, makes the problem of such identification in aerial images interesting. Primarily, this work proposes a detection algorithm using depth information for identification of static vehicles, particularly in parking lots. The scene depth is obtained from Digital Surface Model (DSM) of the urban landscape. Finally, the dependence of performance on the 3D model parameters is analyzed.


From the approaches proposed by various researchers in the community, [1, 2, 3, 4] are closely related to the current work. [1] provides the 3D model of the landscape used in the proposed algorithm. Depth features have been explored for vehicle identification by B. Yang et al. in [2]. However, [2] uses LIDAR data unlike [1] which uses stream of aerial images for estimating scene depth.
In this work, depth features are obtained from [1], which itself is a novel technique to simultaneously solve for camera positions and dense depth estimation. For a given image, height is backprojected onto it using the 3D model. Haar-like features are used for a small portion of the image using sliding window, to estimate the presence or absence of a vehicle. In order to improve the accuracy, validation is incorporated using the edge-saliency of wire frame model as proposed in [4]. To understand the behavior of the system better, analysis of the performance is performed by varying the parameters of optical flow (regularization term, number of iterations, etc.) used in 3D model generation. A high negative correlation between the regularization term and accuracy of the system can be clearly concluded. This analysis can be used to better the overall system thereby an indicative of the scope for improvement.
####References:
- Zhouliang Kang, Gerard Medioni. 3D Urban Reconstruction from Wide Area Aerial Surveillance Video. Workshop on Applications for Aerial Video Exploitation (WAVE), 2015. [Paper]
- Bo Yang, Pramod Sharma, Ram Nevatia. Vehicle Detection from Low Quality Aerial LIDAR Data. [Paper]
- Y. Lin H. Liao and G. Medioni. Aerial 3D reconstruction with line-constrained dynamic programming. In ICCV,2011. [Paper]
- Stefan Hinz. Integrating local and global features for vehicle detection in high resolution aerial imagery. ISPRS Archives,2003, XXXIV(3/W8) [Paper]
Human Activity Recognition
B.Tech project-I, IIT Bombay, Fall 2013
Guide: Prof. Subhasis Chaudhuri
[Report] [Poster]
The need for security and surveillance is always on the rise. This work is an attempt to address this problem in a social gathering using a single, calibrated camera. To begin with, it is a survey of existing methods—studying the advantages and suitability to the problem at hand. Next, a pipeline of approach is proposed similar to the work of Neha et al. in [2]. Finally, suitable improvements are suggested for the scenario considered.
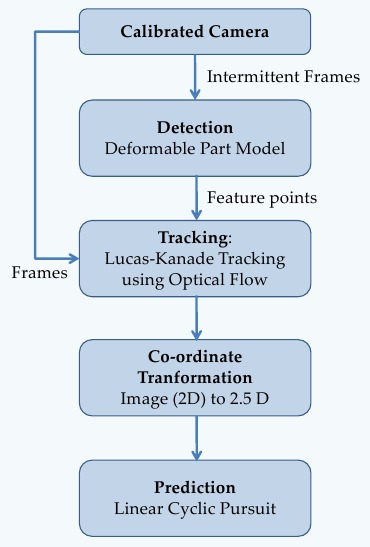
Human Activity is one of the most actively pursued topic owing to its wide range of applications. It has been studied mainly under two approaches—holistic and reductionist. The former considers the crowd as a single entity while the latter models individuals seperately and studies their interaction. [1] and [2] provide the respective examples. This work falls under the latter category.


Following a pipeline similar to [2], frames from the calibrated camera are used to detect humans. Deformable part models ([5]) is employed for the first stage of detection. Due to high computation time, only intermittent frames are used to identify humans and corresponding parts. These detected parts form the feature points and are tracked by the Lucas-Kanade algorithm for remaining frames. This reduces the overall complexity and makes the execution real-time. The feature points on the image plane (2D) are converted to 3D points in world co-ordinates (classically known as 2.5D) using average height plane assumption. Finally, linear cylic pursuit model (LCP) is employed to predict the short-term trajectories of these points for further analysis. Finer details can be found in the report.
####References:
- Viswanthan Srikrishnan and Subhasis Chaudhuri. Crowd motion analysis using linear cyclic pursuit.In Pattern Recognition (ICPR), 2010 20th International Conference on, pages 3340–3343. IEEE, 2010.
- Neha Bhargava, Subhasis Chaudhuri and Guna Seetharaman. Linear cyclic pursuit based prediction of personal space violation in surveillance video. Applied Imagery Pattern Recognition Workshop, 2013.
- Arpita Sinha. Multi-agent consensus using generalized cyclic pursuit strategies. 2009.
- Carlo Tomasi and Takeo Kanade. Detection and tracking of point features. International Journal of Computer Vision, 1991.
- P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part based models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(9):1627–1645, 2010.
Parallel Simulation of Verilog HDL designs
Internship, IIT Bombay, Summer 2012
Guide: Prof. Sachin Patkar
Digital designs, before synthesis, are simulated on a computer platform to test their efficiency. Maximizing the performance and minimizing the overheads is, therefore, a vital area of research. The main focus of this work is to parallelize the simulation of single clock structural/behavior hardware designs without any time or resource conflict. Thus, resulting in a multi-fold in reduction in execution time.

Due to advancements in the multi-core precessors, it is possible to simulate parallelizable designs faster. The flow of the work is briefly given below:
- A given hardware design is converted into a standard XML structure. This allows the feasibility of using any description language (Verilog, in this case) for multi-platform compatibility.
- This XML structure can be parsed in any high level language (Python) using standard libraries.
- The design is systematically analyzed in the high level language to find functionally independent units.
- These independent components are launched as seperate threads on a multi-core platform resulting in an overall reduction in time of simulation.
I have been awarded Undergraduate Research Award (URA 01) for contribution to research at IIT Bombay for this work.
Since this work has been done in close association with a graduate student, most of the implementation details can be found in his thesis report here.
[TOP] [BACK]